Dify¶
Dify is an open-source LLM app development platform. Its intuitive interface combines agentic AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more, allowing you to quickly move from prototype to production.
It supports vLLM as a model provider to efficiently serve large language models.
This guide walks you through deploying Dify using a vLLM backend.
Prerequisites¶
Set up the vLLM environment:
And install Docker and Docker Compose.
Deploy¶
-
Start the vLLM server with the supported chat completion model, e.g.
-
Start the Dify server with docker compose (details):
-
Open the browser to access
http://localhost/install, config the basic login information and login. -
In the top-right user menu (under the profile icon), go to Settings, then click
Model Provider, and locate thevLLMprovider to install it. -
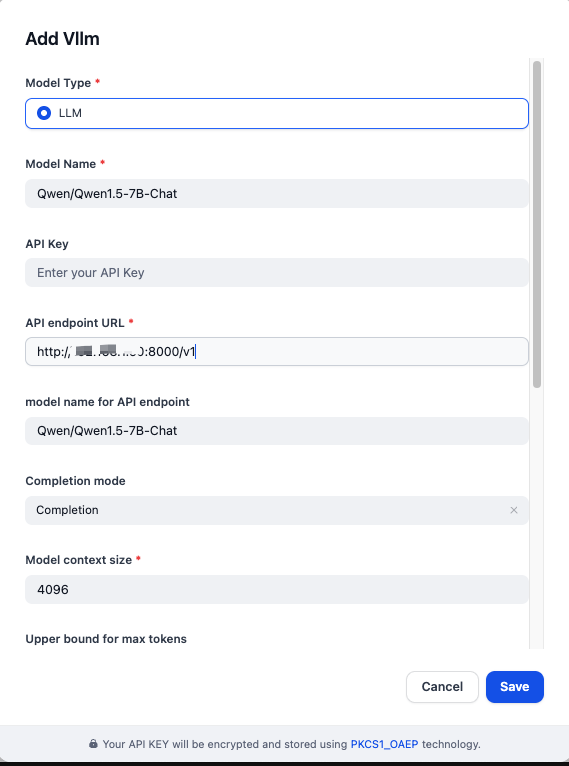
Fill in the model provider details as follows:
- Model Type:
LLM - Model Name:
Qwen/Qwen1.5-7B-Chat - API Endpoint URL:
http://{vllm_server_host}:{vllm_server_port}/v1 - Model Name for API Endpoint:
Qwen/Qwen1.5-7B-Chat - Completion Mode:
Completion
- Model Type:
-
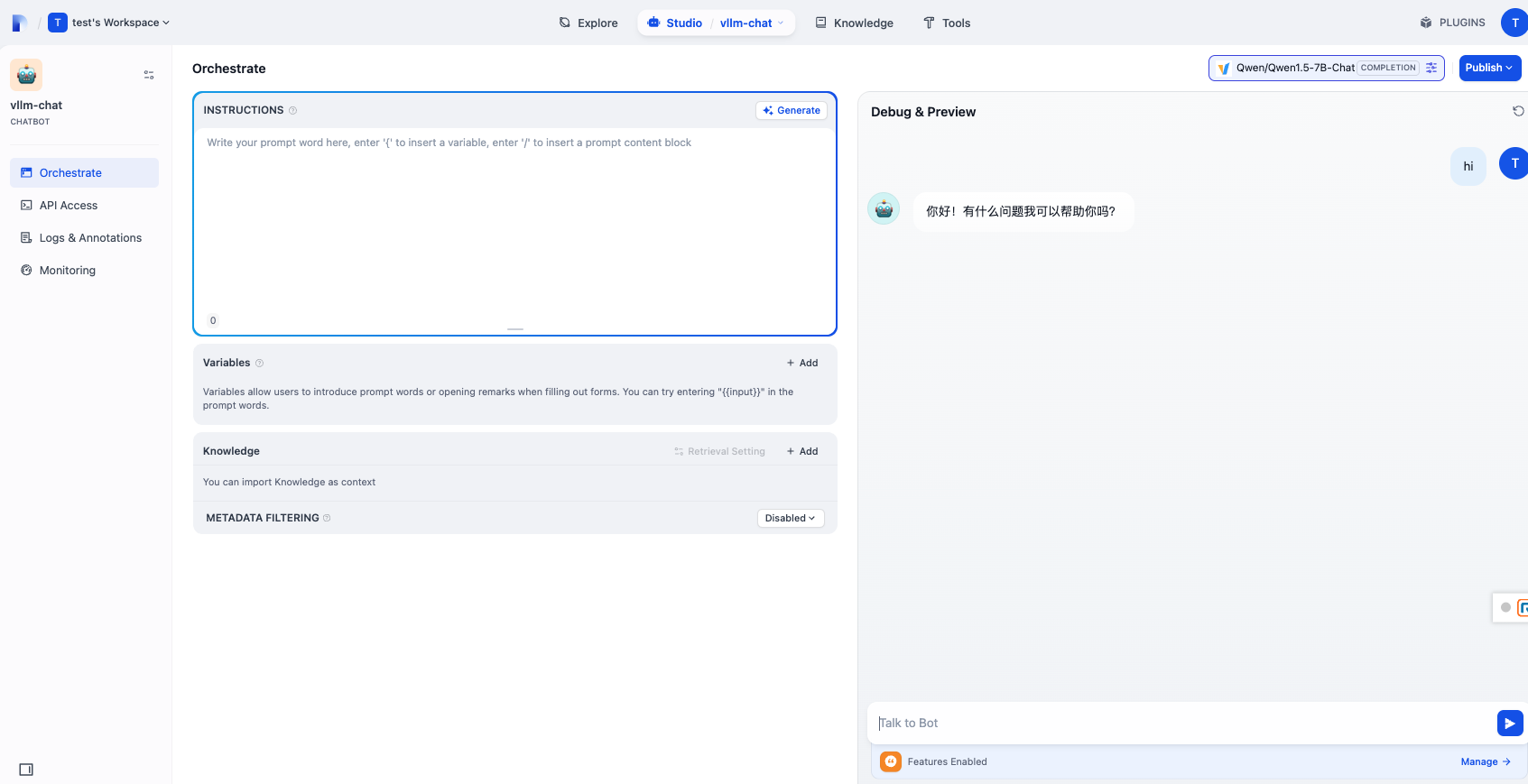
To create a test chatbot, go to
Studio → Chatbot → Create from Blank, then select Chatbot as the type: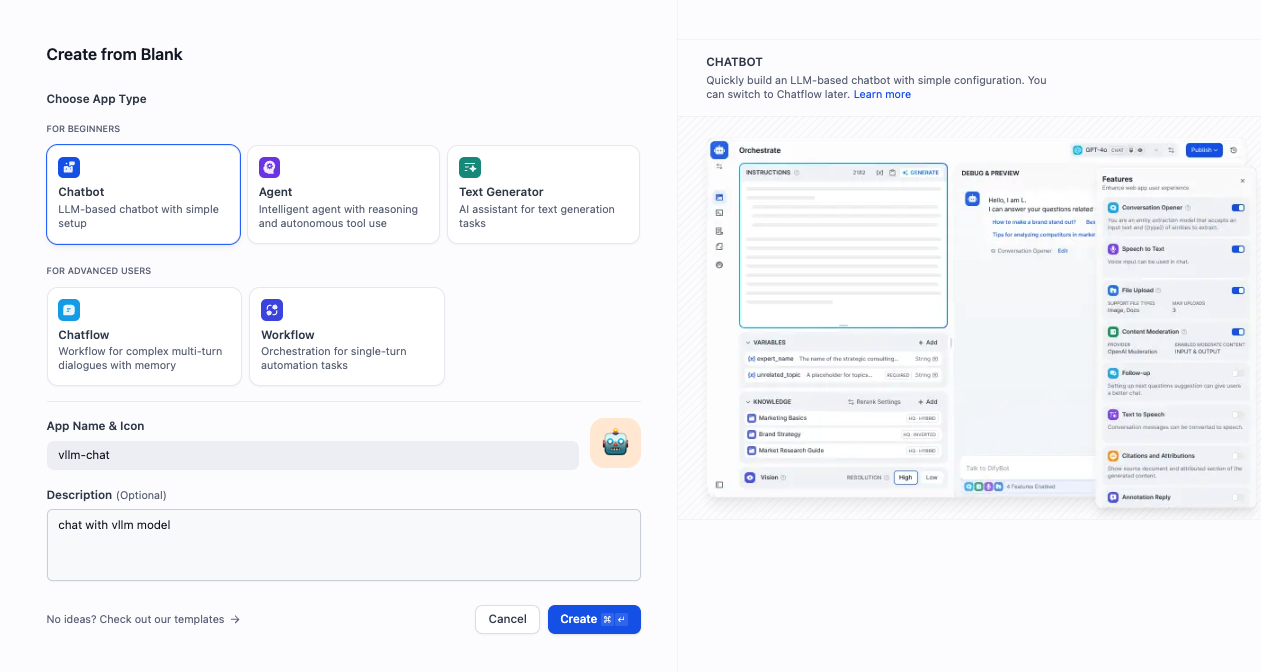
-
Click the chatbot you just created to open the chat interface and start interacting with the model: